
Neo4j is a graph database that differs from a more traditional relational database (like a SQL database, for example) in the way that it stores relationships between nodes. While a relational database can hold foreign keys that reference other model instances, Neo4j has edges that connect nodes, and these edges are POWERFUL. An edge isn’t just a blank connection, it can hold information about the connection and has a direction. If I follow you on Twitter, there might be an edge connecting our nodes that says how long I’ve been following you (I have no idea how Twitter works, is that obvious?) The node would be unidirectional if I’m following you and you’re not following me, or it could be bi-directional if we’re mutually following one another. Queries are also written differently, in a language called Cypher.
Just as thinking about database relationships in graph form involve a bit of a paradigm shift, thinking about seeding data involves similar flexibility.
A bare-bones PostgreSQL seed file may have a function like this:
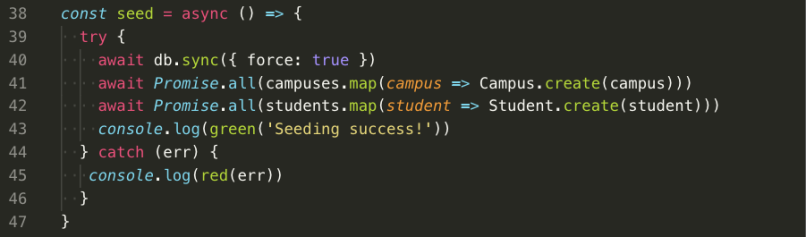
I’ve imported my database (db) where I defined all of my models, and I’m mapping over a campus array and a student array. Both of these arrays contain instances that match up to the way I set up the models.
Neo4j seeding is a similar idea, but different in actual implementation. The similarity is in what you’re feeding into your seed file. It’s still expecting some data structure that contains a bunch of future-nodes – the things you’re putting in your database. For this particular project, I was seeding my database with recipes and ingredients.
Here’s what one recipe looks like. The recipes were generated as a result of scraping a website, so they were kind of wonky JSON objects:
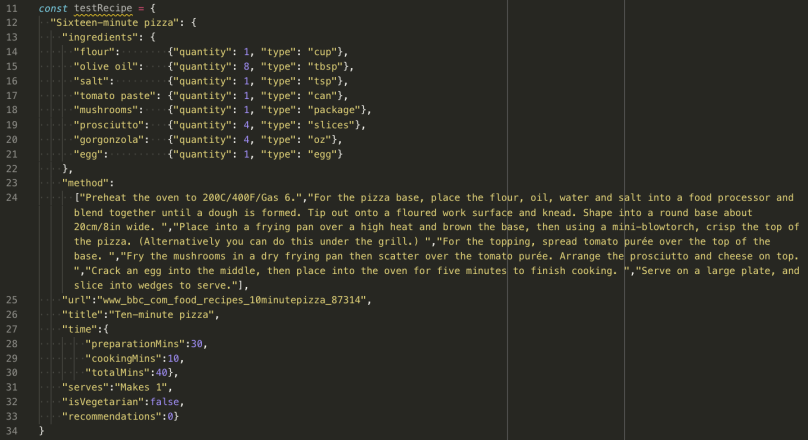
Okay, onto the actual seeding. The function that is actually invoked within this seed file is called runSeed. It’s essentially a helper function with some helpful console logs and 2 asynchronous functions, recipeSeeder and seed, nested inside of a try/catch.
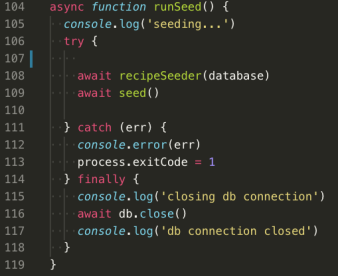
The seed function being invoked within runSeed is just like the PostgreSQL campus/student seed file discussed above. For this project, we used the Neo4j database for everything, but we also had users stored in a relational database because our boilerplate code already included login/sign-up functionality that relied on it. Why fix what ain’t broke? We kept it.
The recipeSeeder function is what we wrote to create the rest. It does 4 major tasks:
- It finds all nodes currently in the database, and deletes them. This is the equivalent of running db.sync({force: true}). We get a clean slate to start seeding.
- It makes assertions for the nodes we’re about to create. We asserted that the recipe names were unique and that the ingredient names were unique.
- It maps over all the recipes in the database it receives as an argument and runs a Cypher query to create a new Recipe node if it doesn’t exist already.
- It maps over all the recipe’s ingredients and runs another query to create new Ingredient node if it doesn’t exist already.
Here’s the function as a whole:
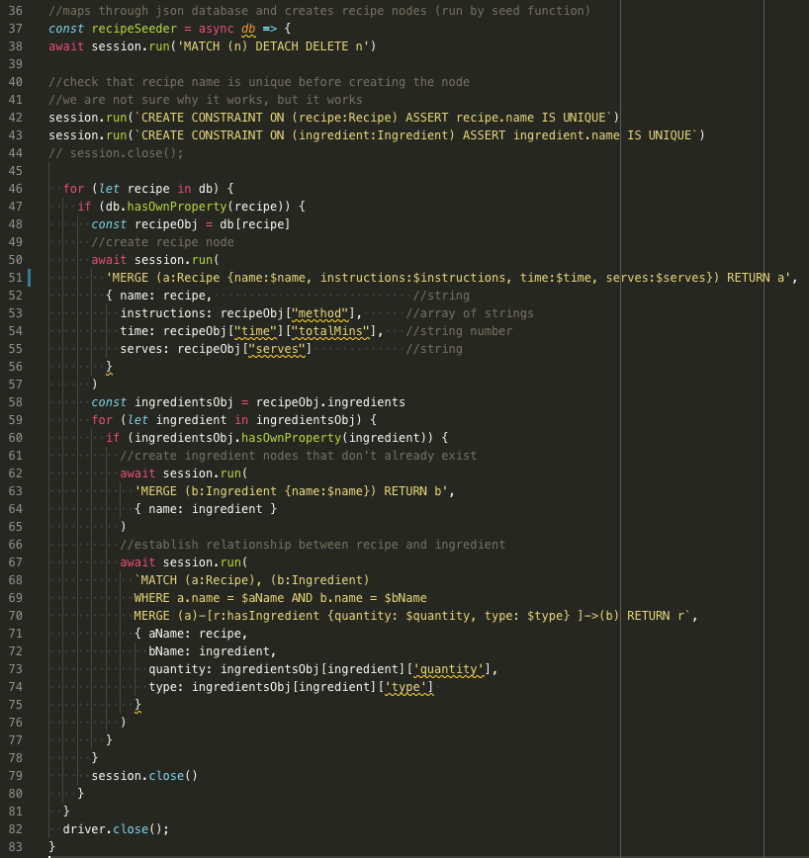
I thought about deleting the comments before adding this picture, but I added them to explain to my group members what was happening and I think that they’re helpful. Same with my linter’s yellow squiggles – this is in-progress code here!
Lines 37 – 43 are doing the housekeeping: clean up all prior nodes, and make sure Neo4j knows we don’t want any duplicates.
Lines 46 – 57 are creating the Recipe nodes. The Cypher query is in yellow. MERGE finds an existing node or creates a new node with the parameters included in the braces, and it returns the node it finds or creates. You could use template literals within the query to have the query interpret variables, but the structure used here is more secure and protects against injection.
Lines 58 – 78 are creating the Ingredient nodes. We iterate through the ingredients on the recipe and run another MERGE query, then we build the relationships. MATCH looks for a Recipe node and an Ingredient node, and the WHERE clause specifies what it should be looking for. Here, we want the name of the Recipe to be our current recipe and the name of the Ingredient to be our current ingredient. Then, we use MERGE again to check if there’s already a relationship. If there’s not, MERGE builds it. We decided to place 2 pieces of information on the edge/relationship created: quantity and type. If my recipe calls for 2 tablespoons of honey, quantity would be 2 and type would be tablespoons. This will allow us to implement sliders for increasing recipe quantities later on.
Lines 79 – 83 are more housekeeping: close the session, and close the driver. Tie up everything with a nice, neat little bow. Seeding is done!
Of course, errors are possible. Before we used MERGE we were using CREATE (because that is a logical word to use when you’re trying to create nodes), but because of our unique constraints errors would be thrown if attempting to create a node that already existed. MERGE solved that problem for us. Another weird quirk about Neo4j is that you’ll get an error if you try to seed the database when your connection isn’t open – makes sense, but always takes me by surprise. You need to go into the Neo4j browser and connect before running any queries.
So that’s it! I’ve been using Neo4j for a grand total of 3.5 days at this point, so I’m sure I will look back on this article in a few weeks and groan, but I think it’s beneficial to chronicle my experiences with new technologies nonetheless.
